
Better procedure design using the Fortran pure attribute
23 March 2023
This news article by Dr Paul Bartholomew describes the resolution of an issue that arose when debugging a pure Fortran procedure as part of work related to the ARCHER2 eCSE06-04 project 3decomp: Towards Adaptive Mesh Refinement in the high-order CFD code Xcompact3d.
When writing a function or subroutine in Fortran it is often desirable to give it the pure attribute. Declaring a procedure as pure places certain constraints on what it can do which may allow the compiler to apply additional optimisations, such as in-lining, and some use cases such as elemental procedures may require it. One of these constraints is that the procedure cannot perform I/O, including print'ing to screen; just as these constraints may aid the compiler, the developer may perceive them as a hindrance, especially when debugging the code, leading to objections to the use of pure. I am going to argue that whenever the limitations of a pure procedure feel prohibitive, they are instead indicating a design issue with the code.
Consider code listing 1 which computes one of the coefficients for the compact finite difference scheme presented by (1), given as:
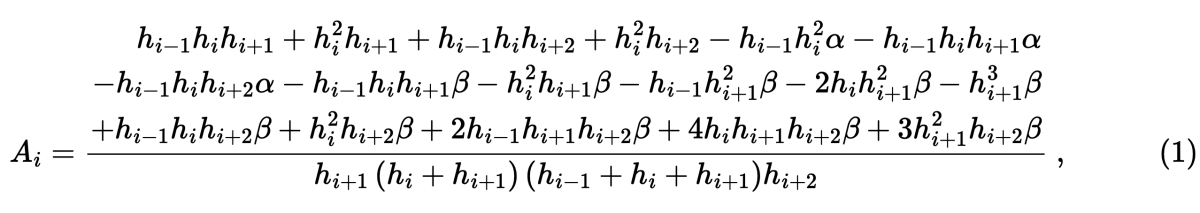
where
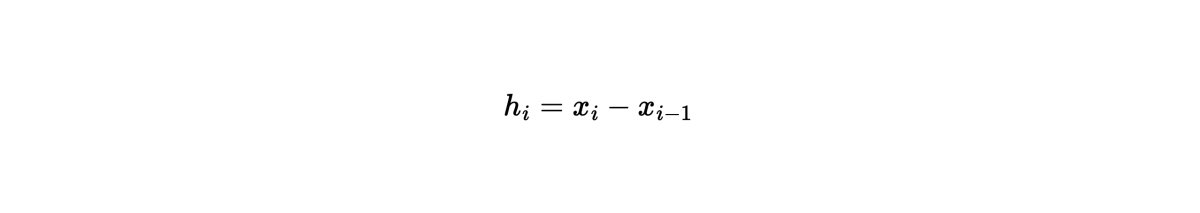
and:
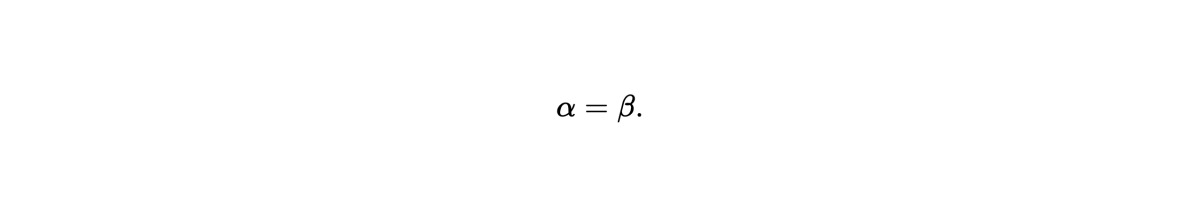
Clearly the implementation of this function will be very susceptible to coding error and requires testing - a simple test is that it reduces to a known function of the grid spacing on uniform grids, with such a test given in listing 2. Even as I implemented this I expected floating point errors to be an issue due to the need to cancel many products of terms of similar magnitude on a uniform grid, however with the gfortran compiler the test passed and all appeared to be well. Testing with crayftn on ARCHER2 however caused a test failure with the result falling outside the range of tolerance for the test, and similarly using ifort on a workstation also caused a test failure. After some investigation it was found that the tests would pass when floating point optimisations were disabled (gfortran also failed the test with optimisations, which are off by default, enabled).
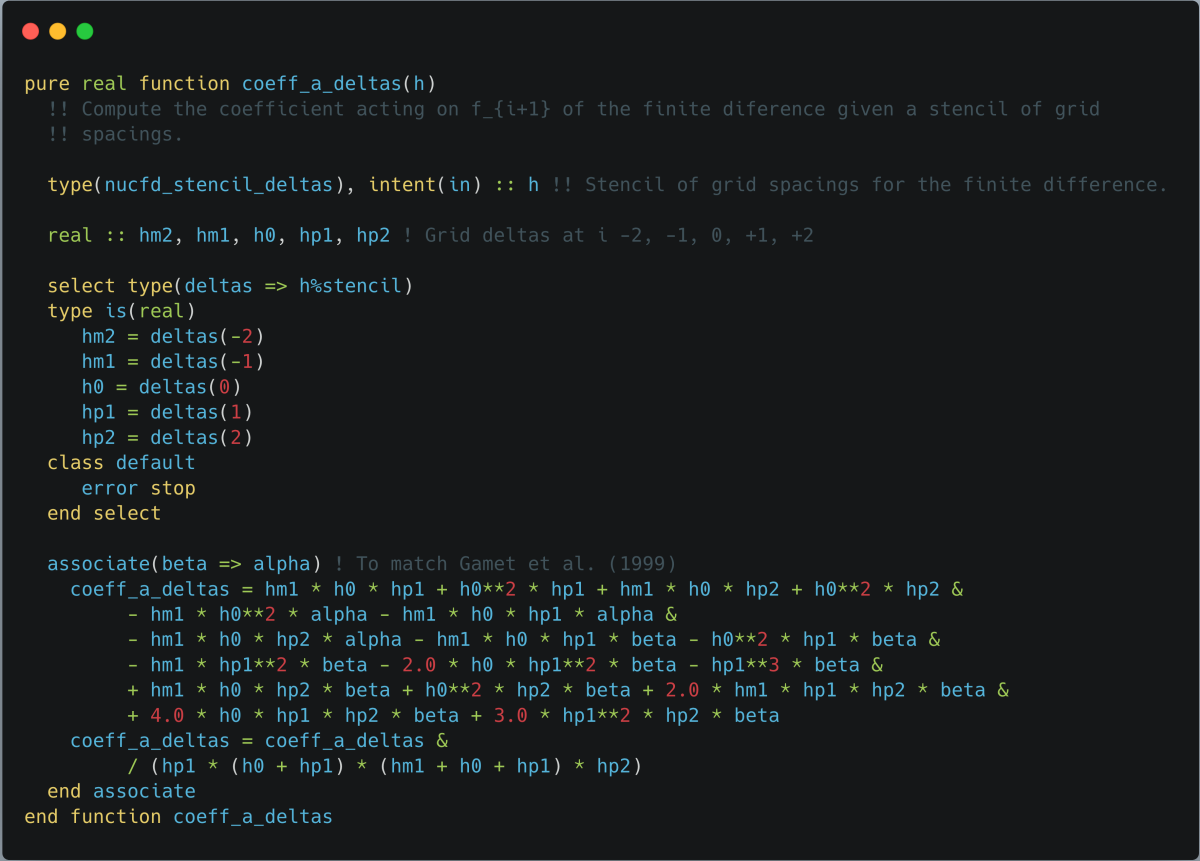
Above: Listing 1 - Original implementation of coefficient evaluation.

Above: Listing 2 - Testing the implementation of coeff_a on a uniform grid.
To debug this problem, I knew what the computed values inside coeff_a should be at various stages so the simplest solution was to remove the pure attribute, insert some print statements and check these values. After some rearranging of the terms I arrived at the implementation shown in listing 3, explicitly grouping terms that cancel, which passed the tests with optimisations enabled, I could then remove the print statements and restore the pure attribute.
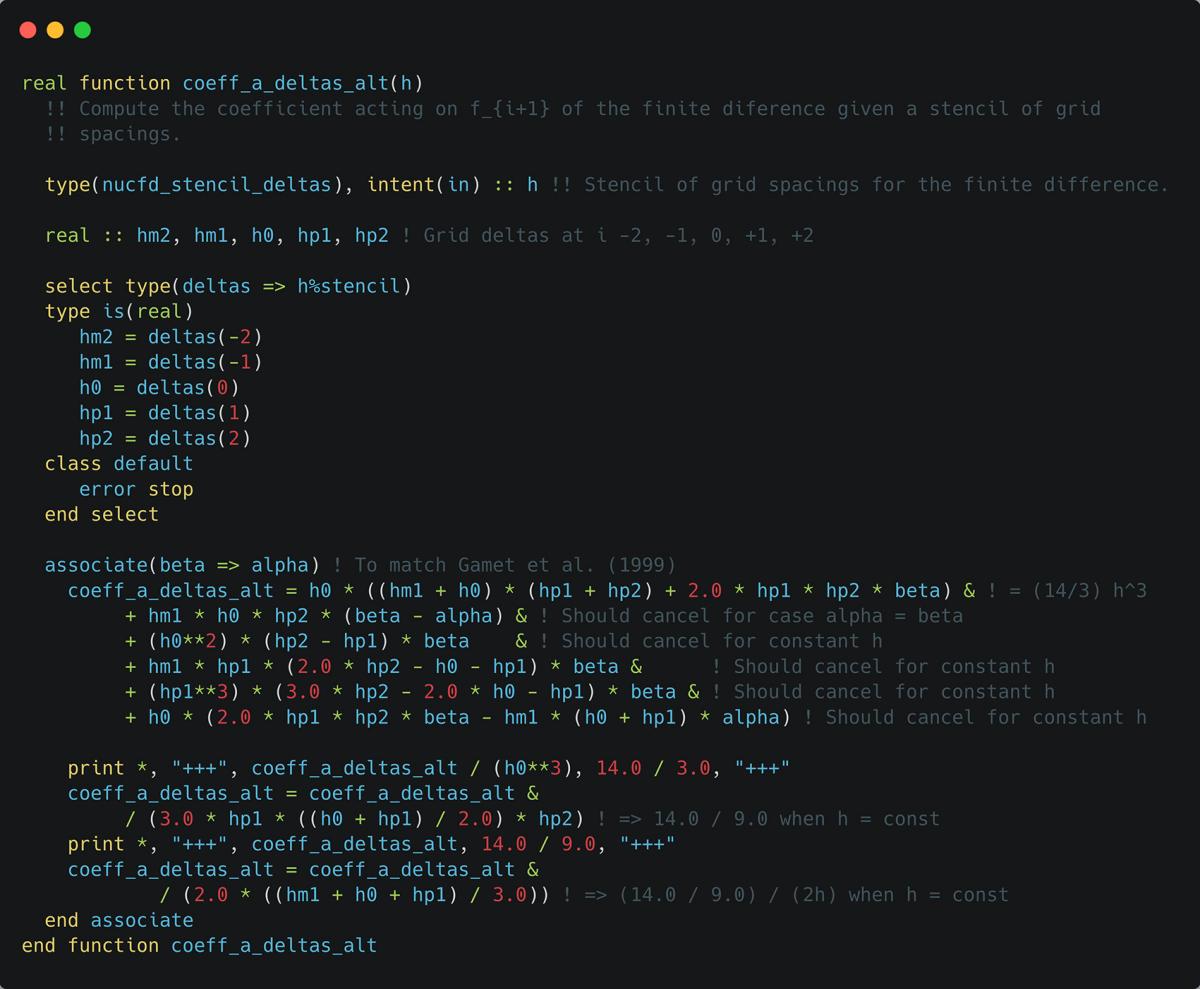
Above: Listing 3 - "Alternative" implementation of coefficient evaluation with debugging print statements.
However, this removal and then restoration of the pure attribute should have been telling me that there was a problem in the design. As noted above, there were several stages to the computation which I knew expected values for — these are themselves pure functions! Rather than temporarily disabling purity I should instead implement each stage as a purefunction, the outer function can then call each of these and assemble the solution from their return values. This is shown in listing 4, the implementation of the functions computing each stage aren't shown for brevity, however they reflect the body of the computation shown in coeff_deltas_alt.
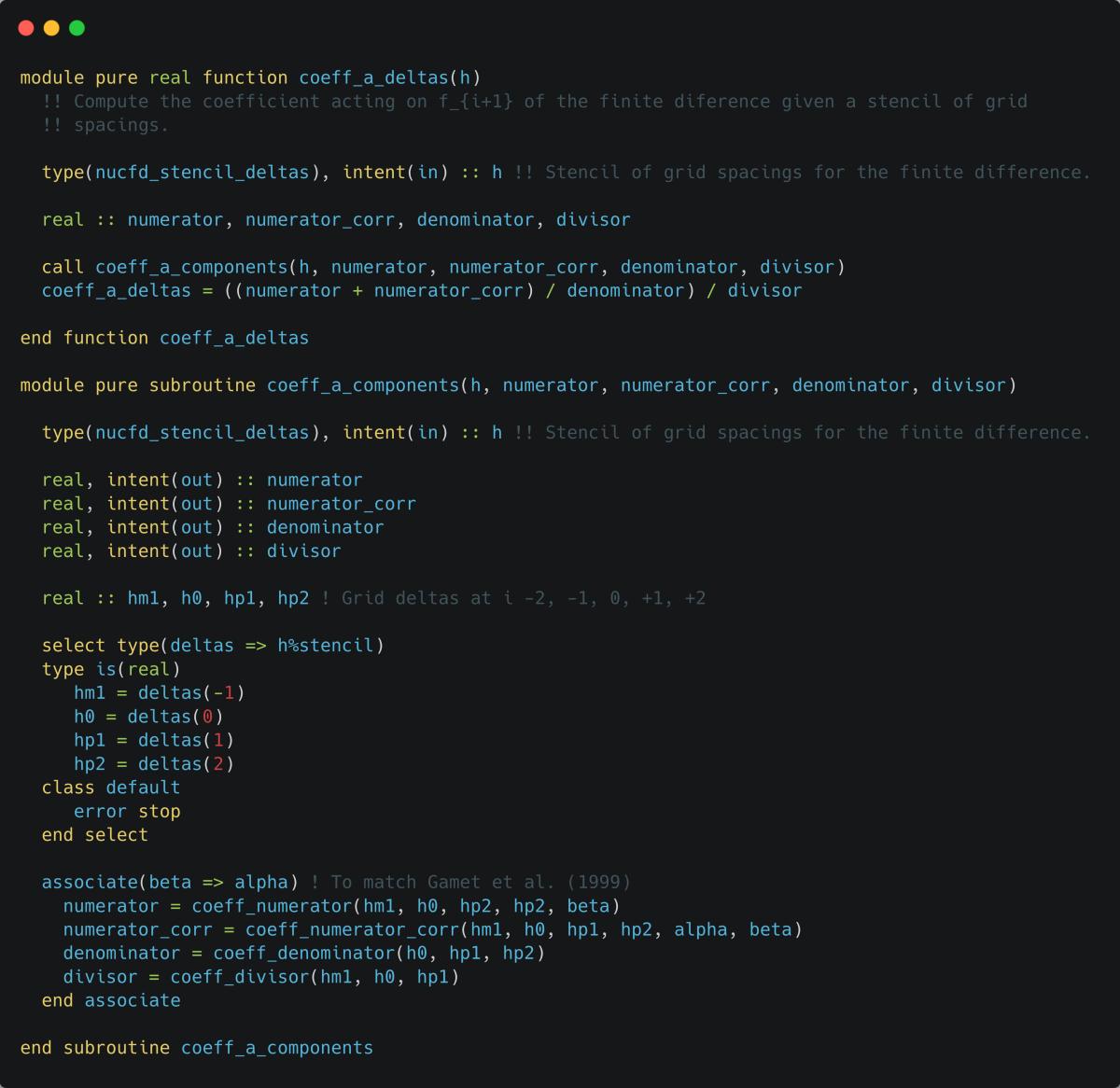
Above: Listing 4 - Improved pure implementation.
As these per-stage functions are relatively low level it is undesirable to expose them outside the module, therefore a helper subroutine (coeff_a_components in listing 4) provides an easy-to-use interface returning the values for each stage. An additional benefit is that I can now test the intermediate values in the test suite, shown in listing 5 making the implementation even more robust!
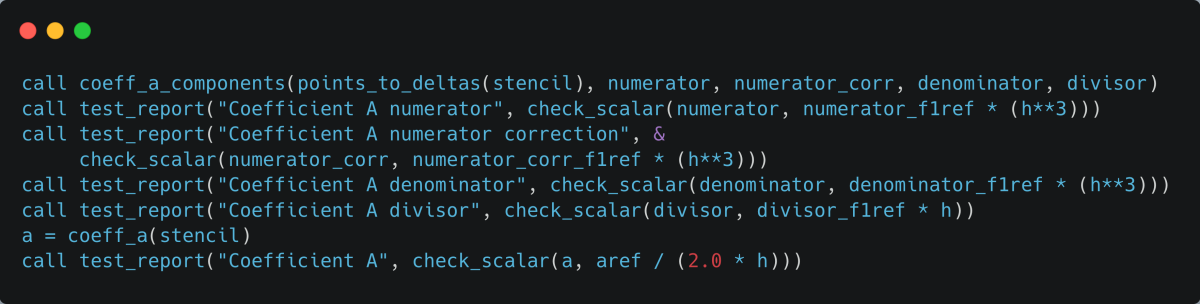
Above: Listing 5 - Expanded test suite based on improved pure implementation.
By retaining the pure attribute, I have arrived at an implementation that is debuggable and better tested than the original. I could have done the same with regular procedures but this requires discipline when simply using print is an easy solution, whereas the use of pure forced us down this design route. In conclusion, pure shouldn't be viewed as a restriction making it difficult to debug failing code, rather when the pure attribute causes friction this likely indicates code design flaws. Wanting to print a variable implies that its value should be tested and the original procedure needs to be further decomposed. To present a user-friendly interface the low-level procedures this creates can be hidden behind a helper subroutine which enables testing and debugging not only the original interface, but also the intermediate values that were formerly untestable.
[1] Gamet, L. and Ducros, F. and Nicoud, F. and Poinsot, T., Compact finite difference schemes on non-uniform meshes. Application to direct numerical simulations of compressible flows, International Journal for Numerical Methods in Fluids, 1999.