
Event Driven Asynchronous Tasks
5 April 2018
The INTERTWinE project has spent a lot of effort addressing interoperability challenges raised by task-based models. By rethinking parallelism in the paradigm of tasks, one reduces synchronisation and decouples the management of parallelism from computation.
This is really attractive but existing models typically rely on shared memory, where the programmer expresses input and output dependencies of tasks based upon variables, which in turn limits the technology to a single memory space – often a node of an HPC machine. So to then scale up beyond a single memory space we must combine a task model with distributed memory technology, such as MPI or GASPI, and this has been a focus for a number of activities in INTERTWinE.
For example, the directory/cache we developed enables the reading and writing of memory held in other memory spaces transparently, so to the programmer it looks like one large shared memory space and without code changes they can run over multiple nodes. But a potential disadvantage of the directory/cache approach is that it places great emphasis on the runtime “doing the correct thing” and the end programmer can lack explicit control over important choices that impact performance. Separately to this, INTERTWinE has also worked on a resource manager and one of the important use-cases for this is to allow tasks to issue MPI communications and then effectively “sleep” until the communications complete. This is important as it means we don’t block a thread, but crucially here the programmer must explicitly combine task and distributed memory paradigms together which can be difficult.
Driving task dependencies through events
INTERTWinE is now coming to a close, and in Edinburgh we are doing a mini-project for the remaining six months around an alternative approach to tasks and task interactions. We are calling this Event Driven Asynchronous Tasks, or EDAT for short.
The programmer still works with the concept of tasks but is explicitly aware of the distributed nature of their code and drives interactions through events. Tasks are scheduled and depend upon a number of events arriving (either from other processes or generated locally) before they are eligible for execution. Events are explicitly “fired” to a target by the programmer and have two purposes: firstly to contribute to the activation of some tasks, and secondly they may contain data that the target task can then process. So based on this description, events effectively contain three key components – a target rank, an event identifier and the optional data payload.
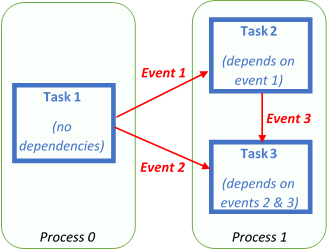
An example of this is illustrated in the diagram, where we have two processes and three tasks. On Process Zero, Task 1 starts immediately (as it has no dependencies) and whilst it is running it fires two events which, based on the programmer's code, are both sent to Process One. On Process One there are two tasks scheduled, and the first event arriving from Task 1 running on Process Zero meets the dependency of Task 2, which marks it eligible for execution and hence it is executed by a thread. The second task on Process One, Task 3, has two event dependencies which must be met before it can run. The first of these, Event 2, is sent from Task 1 running on Process Zero and then Task 2, running on Process Two, will send an event (Event 3) to itself, which meets the dependencies of this third task and hence it will be eligible for execution once a thread becomes free. As I said before, all of these events may contain optional data that the tasks can then process.
With the work done so far in INTERTWinE we have focussed on existing task-based models, such as OmpSs and StarPU, where tasks are driven by input and output dependencies expressed as variables. It is our hypothesis that moving away from this and supporting a view of tasks where dependencies and interactions are implicitly expressed in the context of a distributed memory space, as per the example with the programmer scheduling tasks on specific processes and events able to be sent between processes, will enable the programmer to write high performance large-scale task-based codes more effectively. Crucially they will still be abstracted from the mechanism of parallelism but with a general understanding of how their system is interacting and being able to direct things at that level.
Related work
There are some similarities here with RPC approaches, such as Charm++, where the programmer expresses all their code as C++ objects and methods can be called on these remote objects (known as chares.) This remote method invocation will, behind the scenes, transfer all the arguments to the target processes, execute the code and then return the value back. Our approach is different, as it can be applied incrementally where the programmer need not do a “big bang” refactor of all their code to C++ or this RMI style. Also we think our approach might provide more flexibility, where a task waits for a number of dependencies (events to arrive) which can originate from anywhere.
What’s the point?
In addition to experimenting with our approach applied to common computational codes, I think an important use case for this will be irregular applications. Irregular applications are where communication and even the number of tasks are highly unpredictable. We have seen this previously with the in-situ data analytics of MONC, where cores of a processor are shared between simulation and data analytics. Simulation cores “fire and forget” their data over to analytics cores which will then need to communicate to calculate many higher level information values from this. But because different simulation cores across the system can be at different points, then different analytics cores get data at different times and hence the exact nature of communication is unpredictable. In MONC we had to add a considerable amount of complexity to handle the irregular nature of these communications, but we believe that by abstracting these as tasks and events it would instead make the code far simpler and potentially better performing.