
Quantum computing research: energy efficiency of statevector simulation at scale
Quantum statevector simulation represents the full quantum state using a (very) large vector of complex numbers. In quantum computing simulations gates are applied by multiplying the statevector by an even larger matrix. This method is exact and noiseless, so while quantum computing hardware continues to improve, statevector simulation remains the gold standard for algorithm design and development. The biggest drawback of statevector simulation is the amount of memory required. The size of the main vector grows exponentially, it’s 2N where N is the number of qubits represented.
Supercomputing and quantum computing
As part of our work in the Quantum Software Lab we’ve been looking at how we can best use our classical supercomputers to support the development of quantum computing. That includes finding the best simulation software to run on ARCHER2. Some time ago now, we settled on QuEST – it’s parallelised with MPI and OpenMP, easy to compile and run, and most importantly, scales up to very large numbers of nodes. The developers even managed to run a 44-qubit simulation using AWS ParallelCluster recently – of course, we had to see if we could match that! Don’t worry, we can.
A 44-qubit simulation uses a lot of resources however (4,096 nodes to be exact), so it does raise a further question. Is there anything we can do to minimise the energy usage of such a simulation? Regular readers may recall that my PhD student, Jakub Adamski, has already been looking at the energy efficiency of quantum computing simulations, and his poster “Energy Efficient Simulation of Quantum Computing Simulations” won the 2023 CIUK Poster Competition. In that work, we mainly considered the impact of CPU clock frequency (which can now be set by the user on ARCHER2), and found that clocking down slightly to 2GHz was optimal for QuEST. Jakub and ourselves have now extended that work, and found two further ways to reduce the energy consumption of our Quantum Fourier Transform benchmark circuit.
It should come as no surprise that when using 4,096 MPI processes on 4,096 nodes, a lot of time can be spent communicating using the MPI library. However, just how much communication QuEST actually needs to do is heavily dependent on the exact circuit being simulated. The matrices that describe quantum gates are highly sparse and highly structured, but the structure depends on which qubit the gate is applied to. In general, the non-zero values in gates applied to lower index qubits in the register are closer together than those applied to qubits at higher indices. The further apart the non-zero values are, the more likely it is that updating part of the local statevector will require elements from another MPI process.
QuEST does a great job of minimising the number of messages that have to be sent, but it’s still faster if it doesn’t have to send any at all! What this means to the application developer using QuEST is that you may be able to transpile your circuit to minimise the communication required. There are caveats: you probably won’t gain anything if you have to add extra gates (especially SWAP gates) to achieve this, and unsurprisingly the more memory you have on a single node, the easier it is.
As an example, in Figure 1 below we show a standard Quantum Fourier Transform. Note that the controlled phase gates are actually diagonal matrices, so never require MPI communication. The Hadamard and SWAP gates however, may incur a communication penalty depending on their location. In Figure 2 we show a cache-blocked variant, where we have moved the SWAP gates in order to minimise the communication required by the Hadamard gates. It’s not necessarily easy to spot when these type of transpilation optimisations can be made, so in future work we’d like to investigate how the process could be automated.
Figure 1 (below): Standard Quantum Fourier Transform circuit.
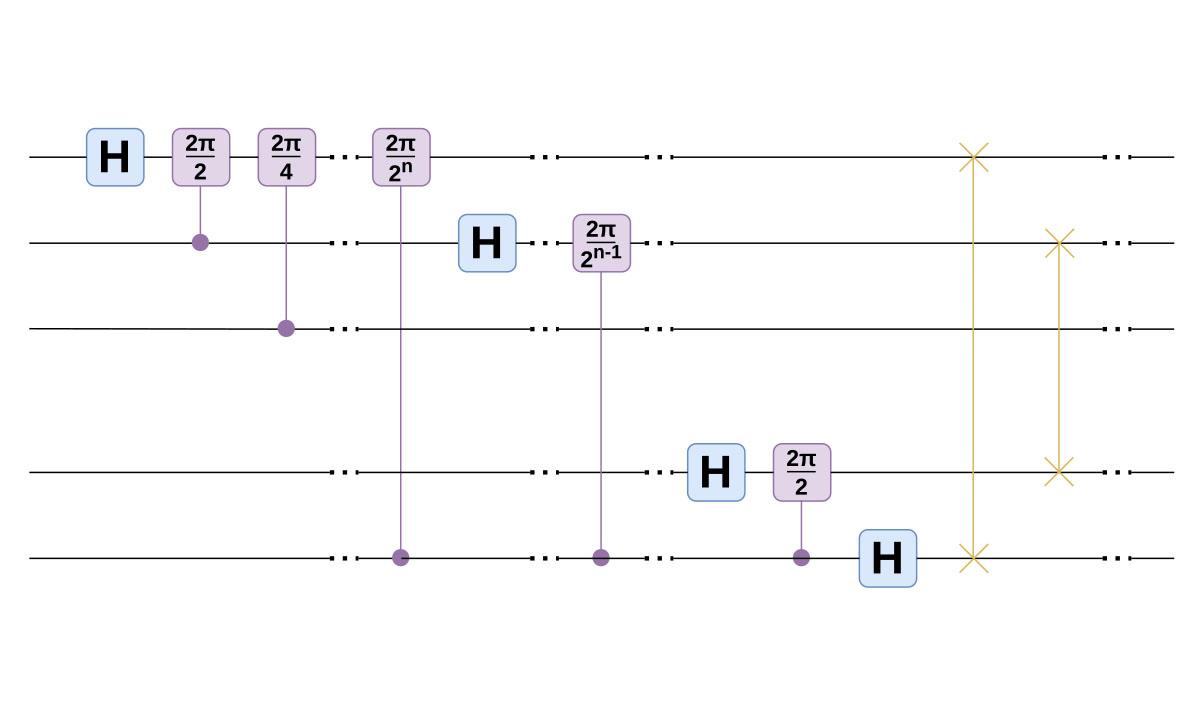
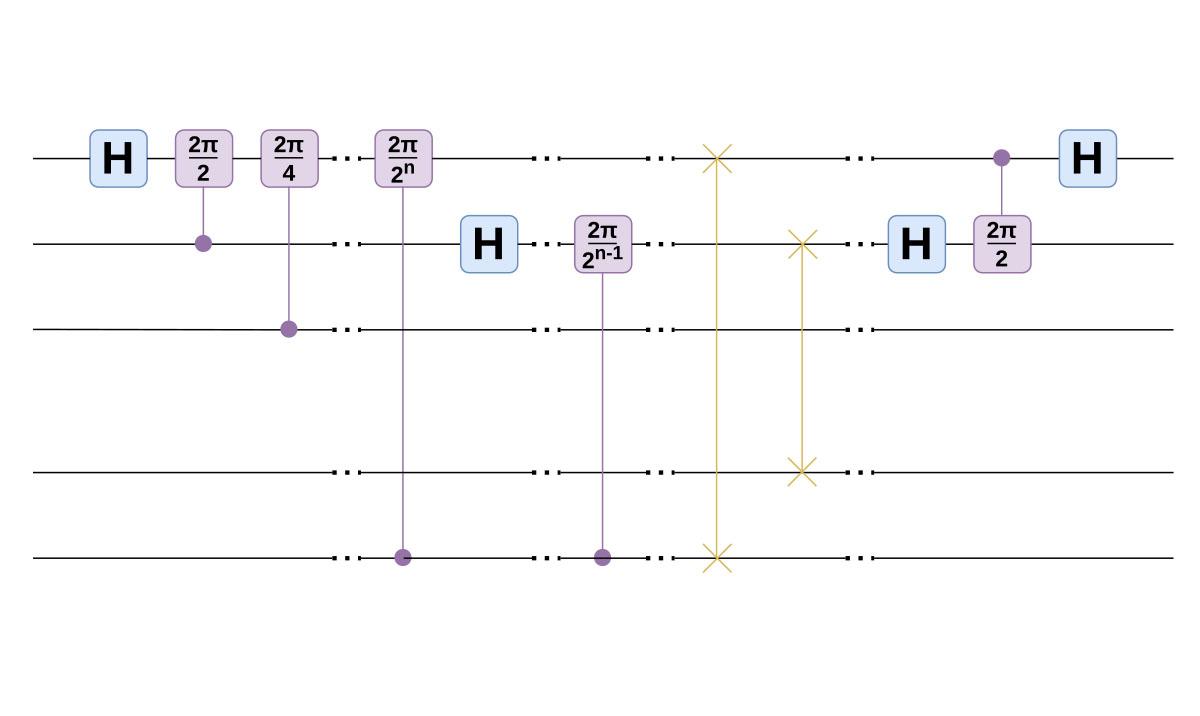
Figure 2 (above): Cache-blocked Quantum Fourier Transform circuit.
This cache-blocking transpilation is the first technique we implemented to reduce the energy usage. The second came from an observation about how QuEST implements its statevector exchange using MPI. The exchange is always done pairwise across all processes, and so quite sensibly uses the MPI_Sendrecv function to overlap sending and receiving and avoid deadlock.
The original design of QuEST was such that it would only ever send two messages from each process in this way for each exchange. Unfortunately, some MPI implementations, and indeed some Network Interface Cards, impose size limits on individual messages necessitating multiple send-receive calls. Since MPI_Sendrecv is a blocking function (one which only returns when it has completed), this imposes a latency penalty, and artificially limits the communication bandwidth.
We modified QuEST to use non-blocking Isend and Irecv calls instead, allowing it to take full advantage of ARCHER2’s bandwidth. The results can be seen in Figure 3 below, which shows profiles of three different circuits running on 64 nodes, using blocking or non-blocking MPI. The first benchmark is a worst-case scenario for communication – a Hadamard gate repeatedly applied to a high-index qubit. The other two benchmarks are the QFT circuits shown in Figures 2 and 3. The green section of the profiles is time spent in compute, orange is time spent accessing memory, and blue is time spent in communication.
The improvement from modifying the MPI is small, but significant. Overall, by applying our cache-blocking transpilation, and using nonblocking MPI we were able to reduce the time spent in MPI when simulating a QFT circuit from 43% of runtime to 25%. Not bad!
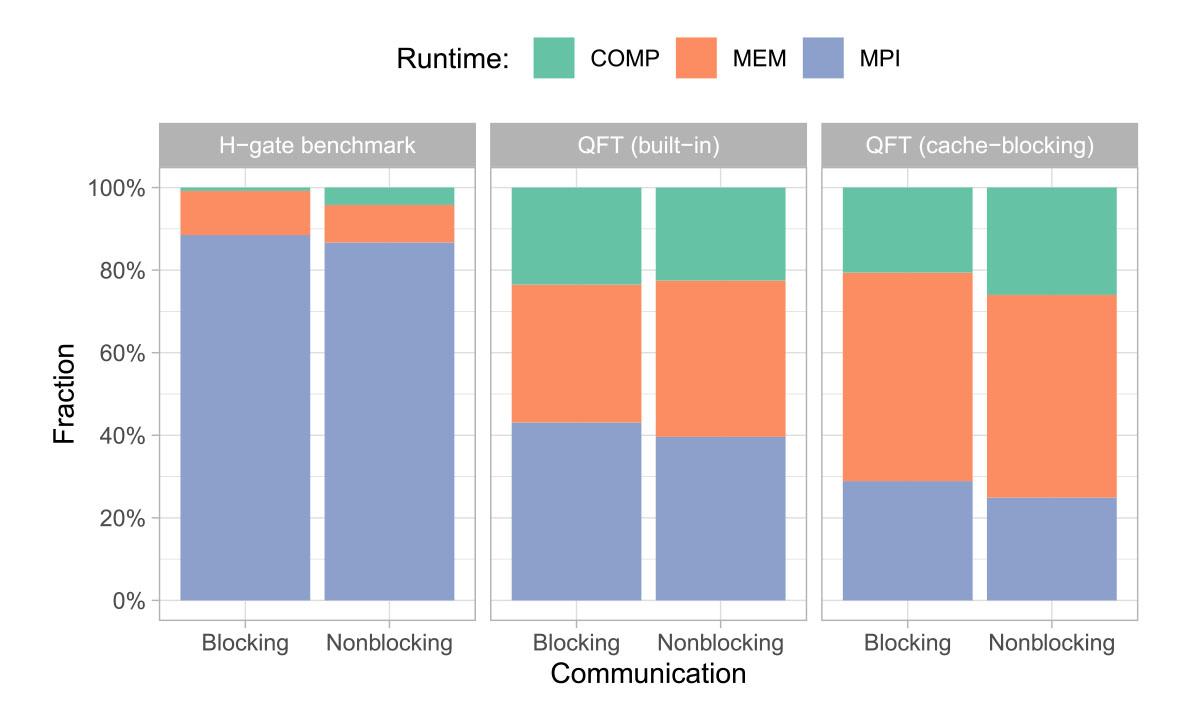
Figure 3 (above): Profiles of QuEST simulating three different circuits, using blocking or non-blocking MPI, on 64 nodes of ARCHER2. The H-gate benchmark is a worst-case for communication.
Energy usage
Now, we said this was about energy efficiency, but so far all we’ve done is talk about performance! Well, that’s partly because when the number of nodes required is fixed by the problem size, all we can do is try to get the simulation to run faster, and with less communication. Don’t worry though, we were checking the energy usage. You can see the final results for our QFT benchmark below. In the end in our 44-qubit simulations we were able to cut 191s off the runtime, and save 233MJ of energy. About the same as boiling 464 kettles*!
Built-in QFT
- Qubits: 43
- Nodes: 2048
- Runtime: 417s
- Energy: 294MJ
Optimised QFT
- Qubits: 43
- Nodes: 2048
- Runtime: 270s
- Energy: 206MJ
Built-in QFT
- Qubits: 44
- Nodes: 4096
- Runtime: 476s
- Energy: 664MJ
Optimised QFT
- Qubits: 44
- Nodes: 4096
- Runtime: 285s
- Energy: 431MJ
So in conclusion: cache-blocking is good, blocking MPI is bad. After returning from a well-earned holiday, Jakub is going to clean-up the MPI change so we can contribute it back upstream to the main QuEST repository. Many thanks once again to Jakub for all his hard work! If you’d like to know more about the study, you can find our paper at arXiv:2308.07402.
*Assuming initial water temperature of 20°C, specific heat capacity of water is 4184J/kg°C,and that kettles have 1.5L capacity, and are perfectly efficient, the energy required to boil 464 kettles is 232.97MJ.
