
You can't fault the filesystem
7 July 2022
EPCC has spent quite a bit of time investigating non-volatile memory functionality and performance for high performance computing, initiated by the NEXTGenIO project. I thought I had a good understanding of the performance of non-volatile memory, and writing programs to exploit it, but a recent foray into novel filesystems threw up some interesting behaviour.
Our standard setup for using B-APM (Byte-Addressable Persistent Memory, also known as NVRAM), specifically Intel Optane DCPMM, is to format it as a single ext4 filesystem per CPU socket and then either use that for standard file I/O, within a distributed filesystem/storage technology such as DAOS, GekkoFS, or CHFS; or program it directly using PMDK.
However, there is a class of filesystems optimised specifically for B-APM, and recently we did some benchmarking of one of these using B-APM. There are a few filesystems that have been designed specifically for non-volatile memory, notable PMFS, NOVA, and the most recent one I've seen, KucoFS. These exploit the performance characteristics of B-APM to undertake data storage operations in a more optimised manner than traditional filesystems designed originally for spinning disks, such as ext4.
B-APM provides very high read and write performance for storage, but also offers high performance for a much wider range of I/O sizes than other storage hardware, even non-volatile memory in SSD and NVMe devices.
The following graph shows the kind of read performance it is possible to get from 1st generation Intel Optane DCPMM memory using an ext4 filesystem, for a range of I/O operations sizes, from 128 byte I/O operations up to 16 megabytes. The next graph shows the same performance, but for write instead of read (both were collected using the IOR benchmark on a single node with 3TB of Optane memory).
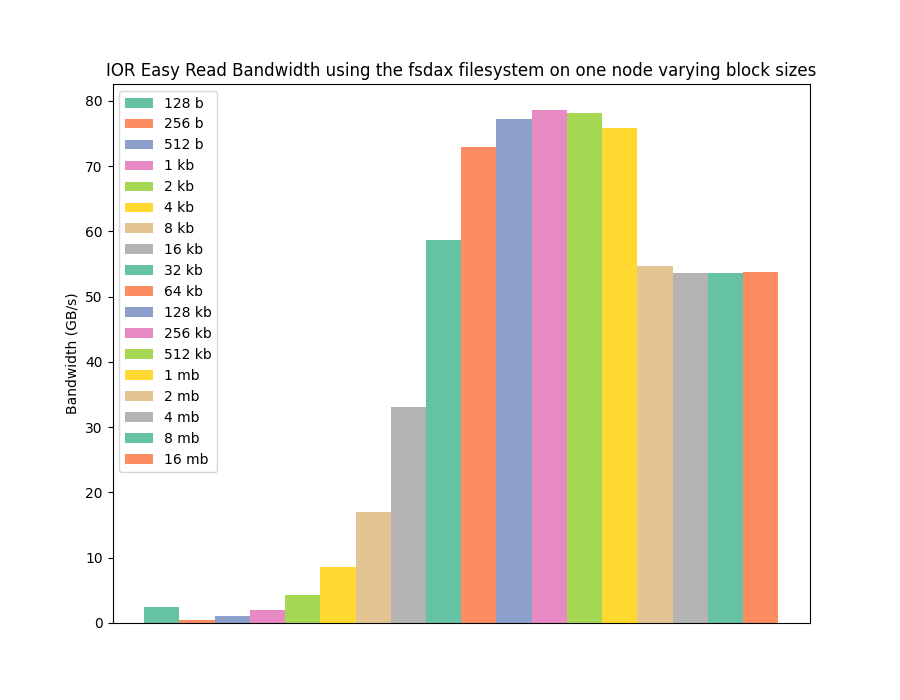
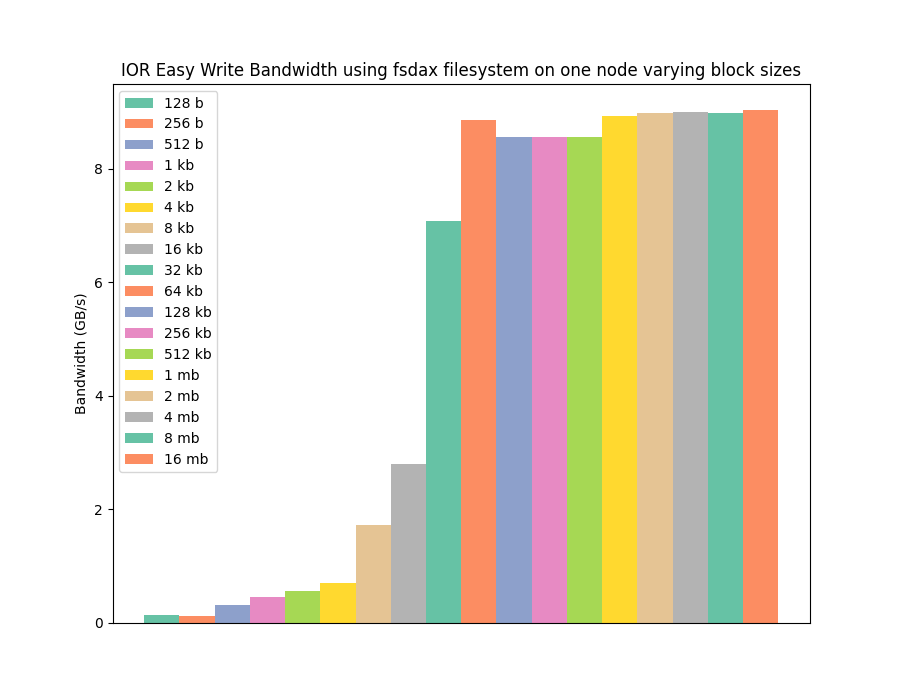
The graphs show that the non-volatile memory can provide high I/O performance, ~10GB/s write and ~60+GB/s read, but using a standard filesystem this only occurs at larger I/O operation sizes. This is in line with traditional I/O hardware, which give best performance when working on large blocks of data (say 4kb blocks) due to the asynchronous and slow nature of the spinning disks traditionally used for storage.
However, we know B-APM can provide high performance all the way down to 256 byte operations, as fundamentally it's a memory technology, and is accessed via standard memory operations in the same way DRAM would be accessed. For the type of platforms we are using, 64 bytes is a standard cache line, so the level of performance granularity should be 64 byte for B-APM. But, with the first generation of Intel Optane DCPMM the actual B-APM itself works on 256 byte data chunks, at least inside the memory chip, hence the 256 byte limit for best performance.
To be able to experience this improved performance at small I/O operation sizes we need to move away from a traditional filesystem approach, and towards treating B-APM as memory, ie programming it with the PMDK interface. The next two graphs show the read and write performance for the same benchmark and configuration as before, but this time using PMDK, rather than POSIX I/O functionality, to access the memory and transfer data.
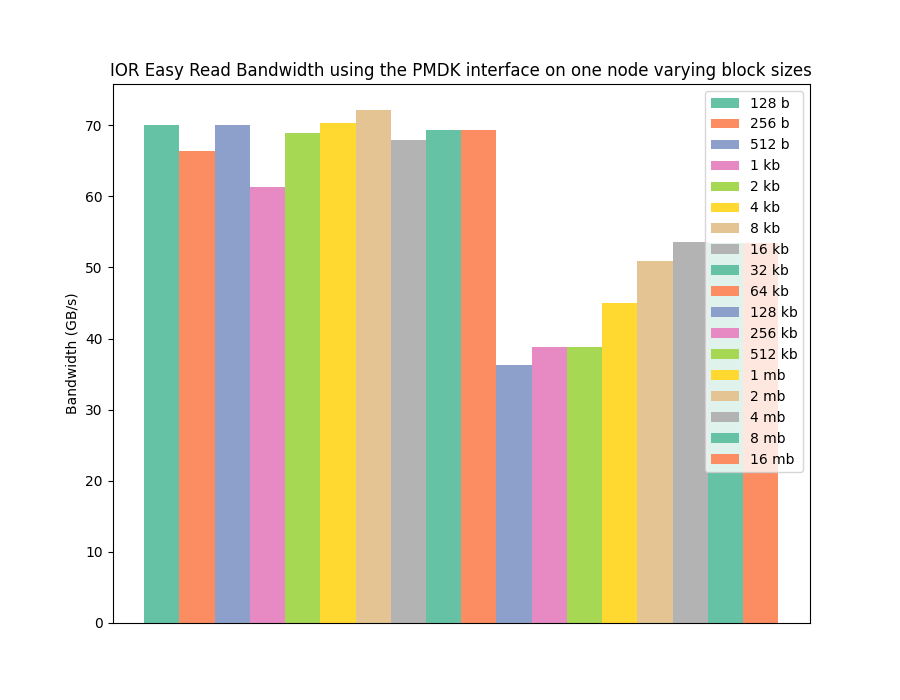
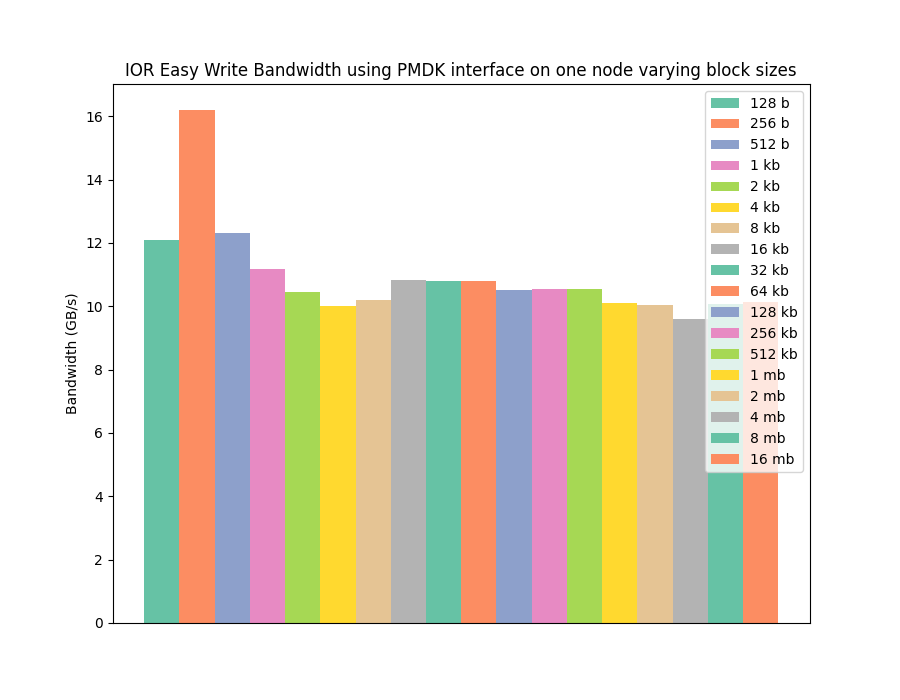
The graphs show that we can achieve similar performance to the filesystem approach, but this time for the full range of I/O sizes benchmarked. This means we can get much higher performance for small I/O operations and can move away from having to program against bulk asynchronous I/O operations. A real demonstration of one of the potential strengths of non-volatile memory.
However, I was interested to see whether a filesystem optimised for B-APM, such as NOVA, could provide better performance without users having to directly program the non-volatile memory using PMDK (which involves changing programs and therefore is a bit of an intrusive approach). Ideally, I'd have targeted the latest B-APM optimised filesystem I'm aware of, KucoFS. Unfortunately, the source code for that does not seem to be available, so I opted for NOVA, which is pretty mature, stable, and available.
As NOVA is a kernel space filesystem, this involved installing a custom linux kernel that included the NOVA functionality. Fortunately, our NEXTGenIO prototype uses Warewulf for provisioning nodes, making deploying a custom operating system Image reasonably straightforward (although more on that in a future article). After configuring a node with NOVA I ran the same benchmarks against the NOVA mounted B-APM, gathering the results presented in the next two graphs.
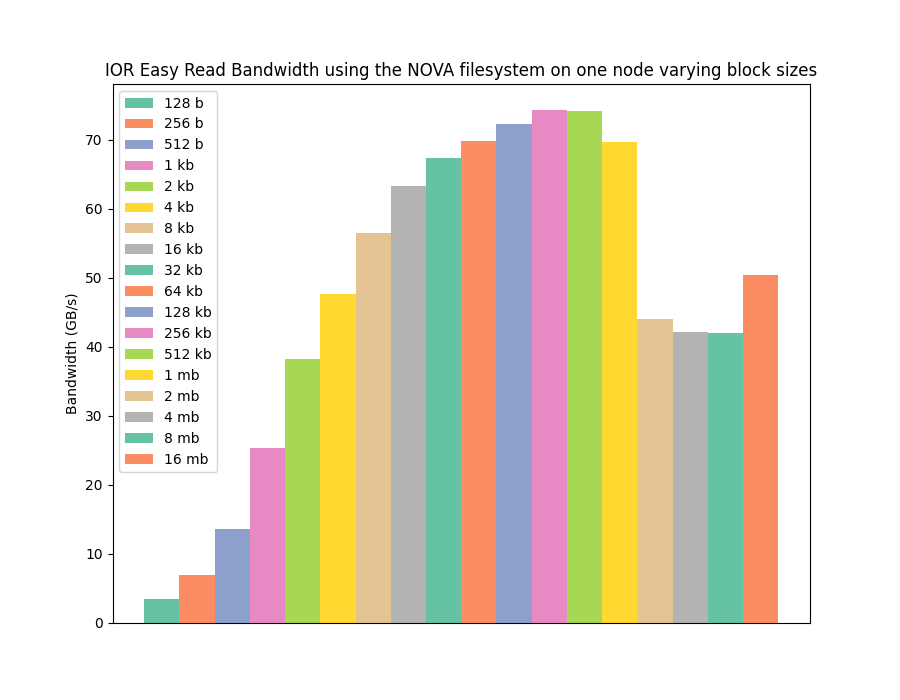
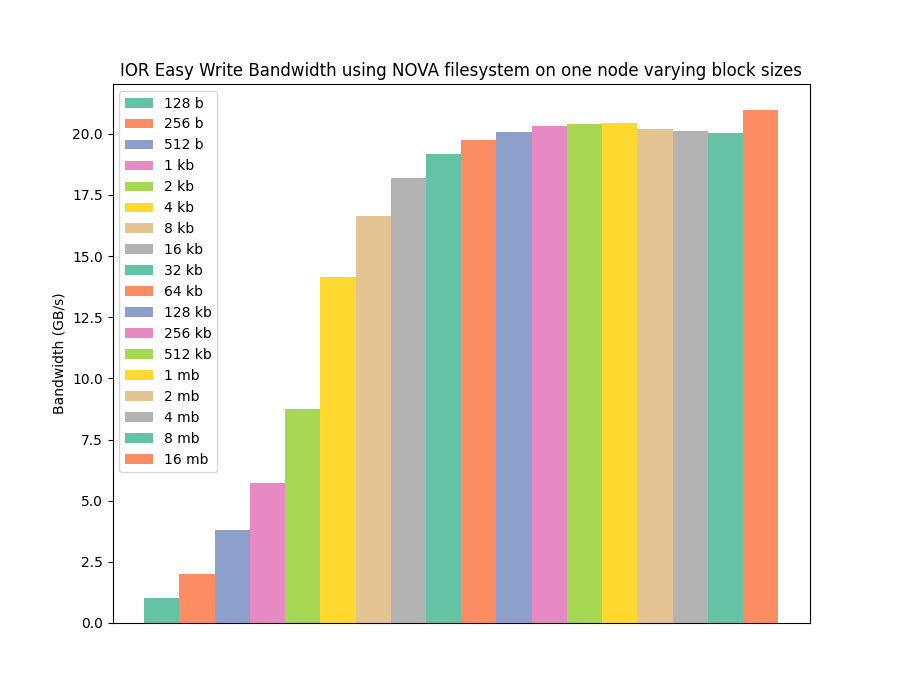
As you can see from the graphs, even a filesystem designed and optimised for non-volatile memory exhibits the same reduced performance for small I/O sizes. It is not as impacted as ext4, but still cannot achieve full performance across the whole range of operations.
However, that wasn't the only interesting feature that can be observed in the benchmarking data. Whilst NOVA demonstrates low performance for small I/O operations, and similar peak read performance as ext4 and PMDK, NOVA is actually achieving significantly higher write performance than both ext4 and PMDK when reaching large I/O sizes!
This result was pretty surprising to me; PMDK treats the B-APM as memory with direct access, bypassing the kernel, page caches, etc... It should be the fastest mechanism for accessing the non-volatile memory, so how is NOVA beating it, and beating it by a large amount, for writing data?
At this point it's probably worth taking a step back and discussing what we're actually using to do the benchmarking here. These results are collected using IOR, a widely used I/O benchmark for HPC workloads and filesystems. It is configured to do a single file per worker, we're using 48 workers per node, and then each worker writes and reads 4GiB of data using a different chunk size for its I/O operations for each bar in the graph(s). So effectively we're doing bulk contiguous writes followed by bulk contiguous reads of the same data. We are bypassing the page cache in all cases to not be influenced by in-memory caching.
This benchmark configuration means that on the write side, the data is simply written from beginning to end. Then it is read back in for the read part of the benchmark. This type of streaming write and then streaming read are not the optimal access pattern for memory, as they incur creation cost with no significant reuse. In a database application, for instance, data is often written once and then read many times, or written many times. However, this mode of operations (streaming writes or streaming reads) is very common for I/O requirements for HPC or machine learning tasks, and therefore is a sensible benchmark target.
It wasn't clear to me how POSIX-based file access on NOVA could provide better performance than PMDK accessing the B-APM directly. After all, once the initial memory space has been created using PMDK then the program should be directly accessing the memory and should just be limited by the hardware characteristics of the B-APM and the memory systems of the processor.
Of course, memory, any form of memory access, is a little bit more complicated than that, particularly at creation of data in memory. From a programming perspective, creating data in memory is generally straightforward. If we take C as an example, you simply need to define a static array, or use the malloc function to create a dynamic array.
As B-APM isn't built into the C programming language, and we need to use the PMDK library to access it from C (or any other programming language) then it's not straightforward to create static arrays or variables in B-APM. However, we can easily create dynamic variables and arrays using the pmem_map_file function from PMDK. This can be considered to be equivalent to malloc, and is what is used within the PMDK backend for the IOR benchmark.
Whilst malloc is simple from a programmers' perspective, it actually is more complex in what it does under the hood, as it's responsible for interfacing with the O/S kernel and its memory management to ask for a new region of memory for this program. That involves the kernel allocating new memory through a page fault if required.
As an aside, this is often why people think that stack memory (statically defined storage) is faster than heap memory (dynamically allocated storage). It's an opinion I hear often from our students, but in reality, once the memory is allocated, it should have exactly the same performance regardless of the allocation space. However, the creation of the initial memory space can take a (comparative) long time. This isn't usually a problem for applications where memory is created once and used often. However, it does mean that applications that create and destroy a lot of memory during their operation, or don't re-use memory once allocated, can see performance overheads associated with this allocation of memory through mechanisms such as malloc.
Anyway, back to our benchmark results and the performance issues we're seeing. The performance variation between POSIX I/O on NOVA and PMDK on ext4 is only apparent on writing data. Read performance is similar between the different approaches. I had assumed that as PMDK enables treating B-APM as memory, then PMDK pmem_file_map would utilise the same page allocator/create mechanism as is exploited for volatile memory, ie what malloc ends up triggering. However, after chatting with the PMDK developers (thanks Piotr!), it transpires that a page fault on an ext4 filesystem under PMDK actually requires an MAP_SYNC configuration, which means that those faults must ensure that all metadata is persisted on return, and this is significantly more expensive than standard memory page faults.
Fortunately, there is a mechanism for using B-APM without using a filesystem backing PMDK at all. Our primary configuration using the ext4 filesystem is known as fsdax (fs standing for filesystem, and dax for direct access). This uses a filesystem to provide the namespace and management of the hardware, as well as enabling multi-tenancy access (ie allowing lots of users or processes to access it safely and securely concurrently).
An alternative mode is possible, devdax, which provides access to the hardware directly as a "device". This does not come with the usability benefits of fsdax, but will enable benchmarking of the hardware without the page faulting functionality we suspect is the performance issue for writing to B-APM.
Using devdax requires a bit of recording for the benchmark, particularly it involves implementing a mechanism to apportion the hardware between all the 48 processes that will be used per node to benchmark the hardware using IOR. After a bit of trial and error and experimentation I was able to benchmark devdax mode and collect data for the following two graphs (same format as before, read then write).
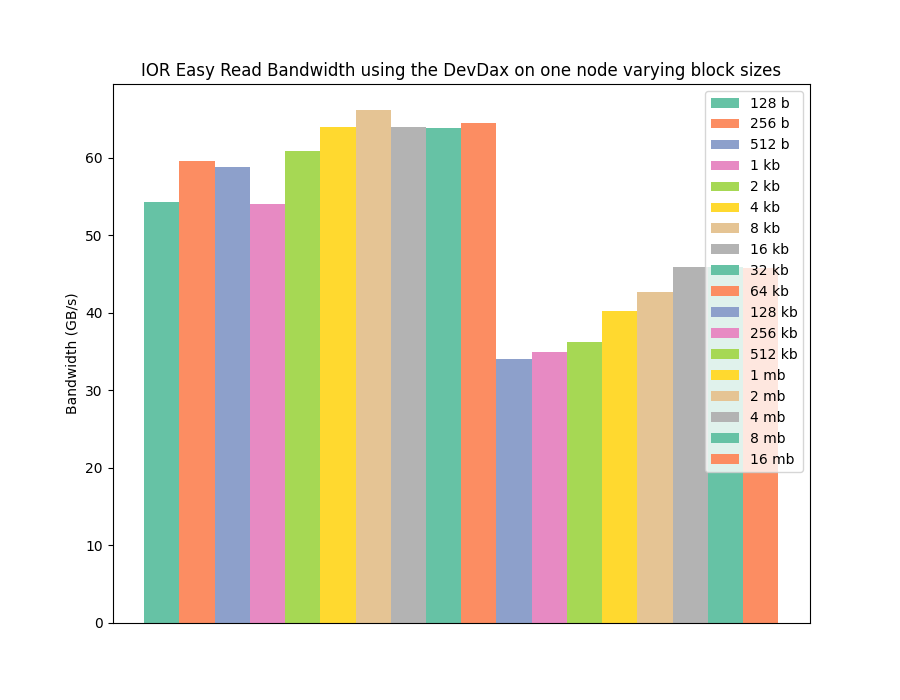
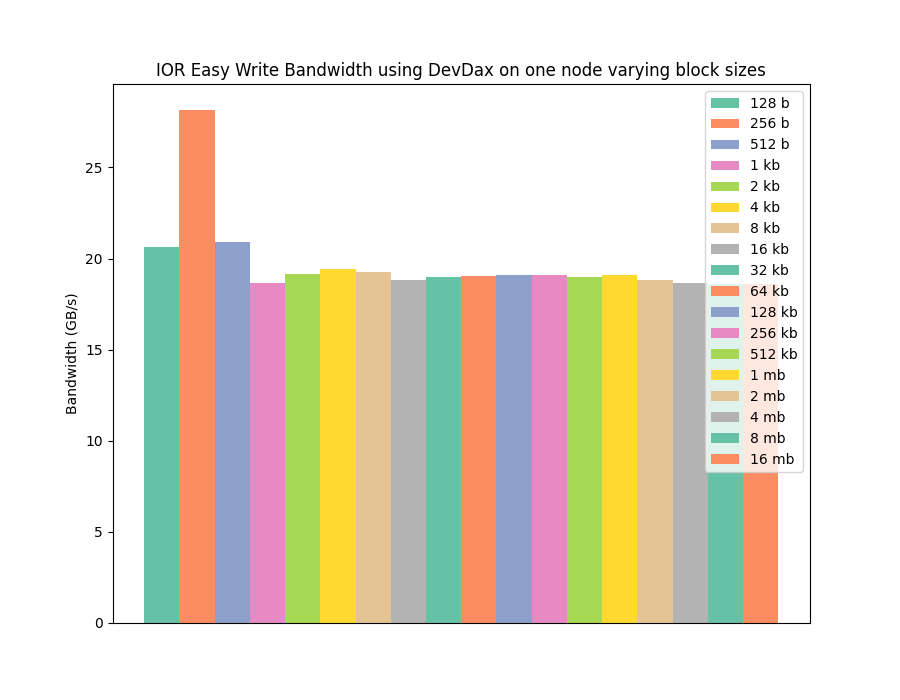
We can see from these graphs that moving to the devdax mode, and manually managing our own memory on the B-APM, we manage to match the write performance of the NOVA filesystem, with the PMDK benefit of achieving that performance at low I/O operation sizes as expected.
Using devdax isn't as convenient from a programming perspective as fsdax, and it's not clear what the security implications of using this mode are (I've not tested whether devdax in a mode where any user can write to it has any options to stop one user's processes reading data written by another user). However, it is clear that for highest write performance where no data re-use is planned and large amounts of I/O are undertaken, devdax is the way to go.
It's also interesting to learn new things about hardware I already thought I fully understood. I did know about the devdax mode and the difference with memory allocations, but I'd just not completely appreciated what that meant from a performance perspective.
It also makes clear that any middleware using B-APM (such as a filesystem, object store, or data manager) may well benefit from exploiting devdax mode rather than fsdax mode.
