
News
New collaboration to explore quantum computing for industrial design and simulation
Quantinuum, Rolls-Royce, Riverlane and EPCC will work together to investigate how fault-tolerant quantum computing could advance complex fluid dynamics simulations, including for uses in gas turbin

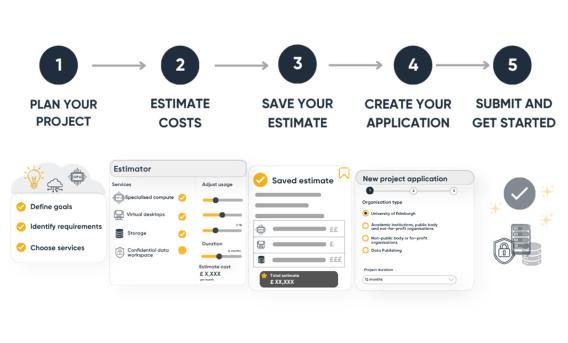
Introducing the new EIDF pricing estimator
A new tool allows users to explore and estimate project costs before creating an account on the Edinburgh International Data Facility.
Rubin Observatory’s Legacy Survey of Space and Time begins
EPCC’s Somerville research cloud hosts the UK's Data Access Centre, which will serve LSST science data to the international community throughout the survey.

CHARTED project: funding available to support Research Technical Professional careers
CHARTED works to make the ecosystem of digital Research Technical Professional (dRTP) skills and roles more transparent and easier to navigate. Join our webinar on July 23 to learn more!

EIDF Drop-In review: smarter tools, clearer costs and safer data
During the Edinburgh International Data Facility drop-in session this month, the team shared a range of new developments designed to make it easier for users to plan, apply for, monitor and manage

UK’s £750m supercomputer milestone as turf cut in Edinburgh
Construction on the site of the UK’s most powerful computer has begun. This is a milestone moment as the UK moves a step closer to turbo-charging its capacity for research and innovation.

Celebrating twenty-five years of EPCC’s MSc in High Performance Computing
EPCC has long been a highly-regarded provider of training in high performance computing, and launched its first Masters programme with the University of Edinburgh In 2001.

Free webinar: 'Demystifying AI'
Pilot-UKAIFA, the UK AI Factory Antenna, will kick off its training programme on 25 June with the webinar 'Demystifying AI'.

Meet EPCC at ISC26
If you're attending ISC High Performance 2026, come say hello to our colleagues and find out the latest about EPCC.

Strategy for Post-Exascale: shaping the European Union future of HPC, AI and Quantum
EPCC is a partner in a new European project to build a dynamic vision for the convergence of high-performance computing, artificial intelligence and quantum computing systems.
