ASiMoV-CCS at the UK National GPU Hackathon
5 April 2023
A team of developers working on the ASiMoV-CCS code joined the recent UK National Open Hackathon which ran from 27 February–8 March, with the main hackathon event running across three days in March 2023. Teams taking part in the hackathon were supported by mentors from OpenHackathons.org in using one of several GPU clusters in the UK, including Cirrus at EPCC, as they worked towards various goals such as optimising codes already running on GPUs or initially porting their code to GPU.

Figure 1: Cirrus front panel. https://www.epcc.ed.ac.uk/hpc-services/cirrus
The Asimov consortium, led by Rolls-Royce and EPCC, was awarded an EPSRC Prosperity Partnership worth £14.7m to develop the next generation of engineering simulation and modelling techniques. The aim is to develop the world’s first high-fidelity simulation of a complete gas-turbine engine during operation.
Team ASiMoV-CCS, with members from EPCC and Rolls-Royce, took part in the hackathon with the goal of demonstrating the capability to run the ASiMoV-CCS code [1] on GPU hardware. ASiMoV-CCS is a general purpose, unstructured CFD and combustion code being developed as part of the ASiMoV EPSRC Strategic Prosperity Partnership in collaboration between EPCC and Rolls-Royce, designed for running large scale simulations on the ARCHER2 supercomputer.
Written in modern Fortran, ASiMoV-CCS makes use of many of the newer features in the Fortran standard. It is designed with an emphasis on modular code that is portable, maintainable and avoids dependency lock-in. However, extensive use of modern Fortran constructs may challenge compiler implementations. We discovered that some of the desired features we need, that are fundamental to our design based on a clear separation-of-concerns, prevented us from compiling the code using the latest version of the NVHPC Fortran compiler, nvfortran, installed on Cirrus (NVHPC 22.11). This presented a challenge for running ASiMoV-CCS on the NVIDIA V100 GPUs installed in Cirrus. Finding a solution to this problem was one of our main motivators for joining the hackathon.
As a starting point, we intended to make use of the CUDA support in PETSc [2] (which we use for the parallel solution of large linear systems) to demonstrate offloading of one of the core components of ASiMoV-CCS. With guidance from our mentors over the course of the hackathon we were able to demonstrate GPU offload of the linear solver via the PETSc CUDA backend. The recent PETSc release series also provides access to AmgX [3], a GPU accelerated open-source solver library that targets computationally intensive linear solver problems, which we tested.
By using the NVIDIA Nsight systems profiler [4], we were able to confirm that the linear solver was being launched on the GPU, as shown in Fig 2. As expected, only the linear solver runs on the GPU in this setup, with other steps such as (re)computing the linear system coefficients running on the CPU, as seen by gaps in the timeline between linear solver launches.
We also began testing our code using the PETSc CUDA backend on multiple GPUs, however this would crash when using the current (3.18.x) version of PETSc. When using CUDA vectors, ghost points were not being allocated, limiting us to running on a single GPU. A fix is available on one of the PETSc branches [5], and the developers have confirmed this will be merged into the main branch and released shortly. Using this branch we were able to perform preliminary testing of running ASiMoV-CCS on multiple GPUs.

Figure 2: Nsight systems profile showing linear solver offloading.
Offloading the linear solver leaves our high-level, abstracted, user code that builds those linear systems as a potential bottleneck with data being transferred between host CPU and the GPU accelerator limiting the performance benefit. Thankfully Team ASiMoV-CCS was paired with a team of mentors from NVIDIA who had solved a similar issue before and were able to point us at a potential solution [6].
By exploiting Fortran-to-C and C-to-Fortran calling conventions, a Fortran code can be written as two components that are compiled separately: one that attempts to call a C procedure and another presenting itself to be called from C. Although our approach using modern Fortran features causes build failures using the latest version of nvfortran available on Cirrus, the modular design of the code this supports meant we could easily isolate the kernels of the user code to be compiled separately for GPU acceleration, using two different compilers. The final result is that the primary compiler is not responsible for accelerator offload and the code it compiles (the majority of the codebase) calls an interface to accelerated code that is compiled separately.
Conceptually this approach of separate compilation is very similar to how we can use an accelerated backend for the linear solvers via the PETSc interface. By doing so we can combine the strengths of two compilers – here gfortran’s support for generic interfaces and nvfortran’s offloading support – in a single codebase, currently this is available on the development branch link-kernel-nvc on GitHub. We confirmed that the kernel computation was being offloaded to GPUs, again using Nsight systems. Although the actual amount of time spent in GPU offloaded kernel code is small, as seen in fig. 3, this shows there is a viable development path for ASiMoV-CCS to exploit the GPU hardware we expect to become more prevalent based on recent trends.
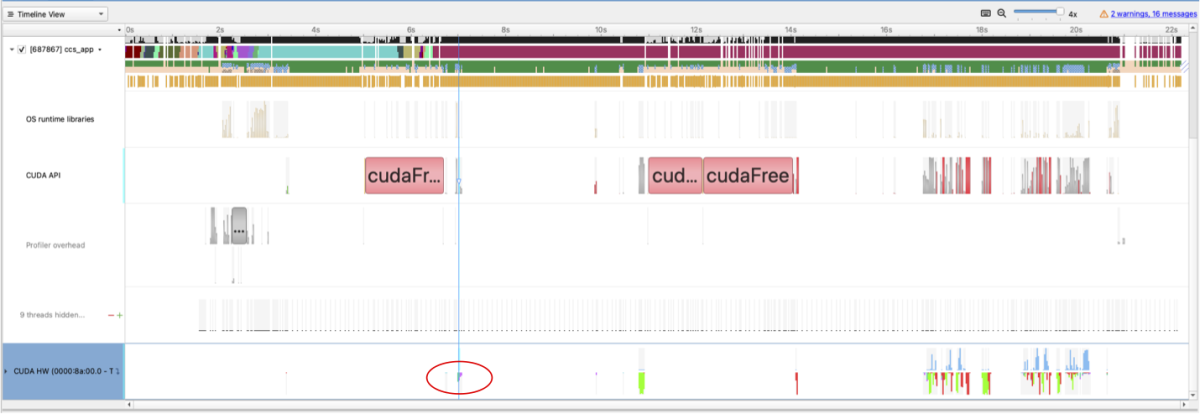
Figure 3: Nsight systems profile with coefficient evaluation offload highlighted in red.
Finally, we took advantage of having rewritten the coefficient evaluation module to begin prototyping an OpenMP-based version, initially targeting CPUs. This will enable us to explore shared memory parallelism for ASiMoV-CCS generally, and to try a single toolchain GPU-accelerated build using the newly installed GCC-12 module with GPU offload support on Cirrus via the OpenMP backend too.
With help from our mentors, we were able to achieve our hackathon goal to develop a proof-of-concept GPU capability combining the PETSc CUDA backend with NVIDIA compiled user code without significantly rewriting the high-level code of ASiMoV-CCS. This is a clear benefit for the potential future development of ASiMoV-CCS and we would encourage other teams to join future hackathons.
NVIDIA has not only kindly supported the activity but also taken our feedback internally to further improve the compiler toolchain. Although there is still significant work required to optimise ASiMoV-CCS for GPU hardware, by demonstrating offload capability this has gone from a seemingly impossible task to one that requires the effort to do so.
This work was completed in part at the UK National Open Hackathon, part of the Open Hackathons program. The authors would like to acknowledge OpenACC-Standard.org for their support.
Team ASiMoV-CCS members and mentors
Paul Bartholomew (EPCC), Matt Bettencourt (NVIDIA), Christopher Goddard (Rolls-Royce), Jeff Hammond (NVIDIA), Sébastien Lemaire (EPCC), Filippo Spiga (NVIDIA), Justs Zarins (EPCC), Michèle Weiland (EPCC).
Footnotes
[1] ASiMoV-CCS is available on GitHub at https://github.com/asimovpp/asimov-ccs. All hackathon work was conducted on the branch gpu-hackathon.
[2] The Portable, Extensible Toolkit for Scientific Computation; https://petsc.org
[3] NVIDIA Algebraic Multigrid Solver (AmgX) library; https://developer.nvidia.com/amgx; https://github.com/NVIDIA/AMGX
[4] https://developer.nvidia.com/nsight-systems
[5] https://gitlab.com/petsc/petsc/-/tree/barry/2021-11-04/add-dmplex-vecgh…
[6] Jeff Hammond; Dealing with Imperfect Fortran Compilers, Part 2; https://github.com/jeffhammond/blog/blob/main/Dealing_with_imperfect_Fortran_compilers_2.md