
Parallelising Macauff photometric catalogue software for the LSST:UK cross-match service
9 June 2023
EPCC is undertaking a number of projects in support of LSST:UK, the United Kingdom participation in the Vera C. Rubin Observatory's Legacy Survey of Space and Time.
The Vera C. Rubin Observatory's Legacy Survey of Space and Time (LSST) stands to produce volumes of data never before seen in the field of astronomy. The telescope will observe object counts in excess of ten times the current largest photometric catalogues and, as such, effective analysis carries more computational complexity than ever. This necessitates the use of high performance computing (HPC) resources to ensure scientific discoveries can be made in a reasonable timescale. Hence, scientific software must be written in such a way as to effectively exploit HPC.
LSST:UK, the United Kingdom participation in LSST, is currently working on a server for catalogue cross-matching, this is the process by which two different astronomical data sets (the catalogues) are compared to identify objects (eg stars and galaxies) which appear in both. At LSST scale, more complex algorithms are needed than those traditionally employed, leading to the development of Macauff, a novel cross-match code by Tom Wilson and Tim Naylor of the University of Exeter.
Macauff is written primarily in Python with small sections of Fortran used for performance-critical kernels. Initial versions employed OpenMP multithreading for shared-memory parallelism but, even at high thread counts, LSST-scale matches were predicted to need months to years to complete on target platforms. I was brought into the LSST:UK project to implement distributed-memory parallelism, allowing the cross-match code to run across multiple compute nodes and perform at scale on HPC services. Our goal was to achieve a factor of 50x speed-up, reducing cross-match runtime to the order of a week.
As a first step in the parallelisation effort, an execution profile of Macauff was established to identify run-time hotspots and inform potential scope for optimisation. The University of Cambridge CSD3 HPC service was the platform for experimental runs of Macauff code commit 77794f4. Performance profiles were gathered with the Python line_profiler module, with source code manually instrumented with “@profile” decorators on relevant function calls. Sample data was sourced from the Gaia and WISE astronomical catalogues and profiling performed on two test cases: a “small” dataset and a “large” dataset with approximately five times the object count.
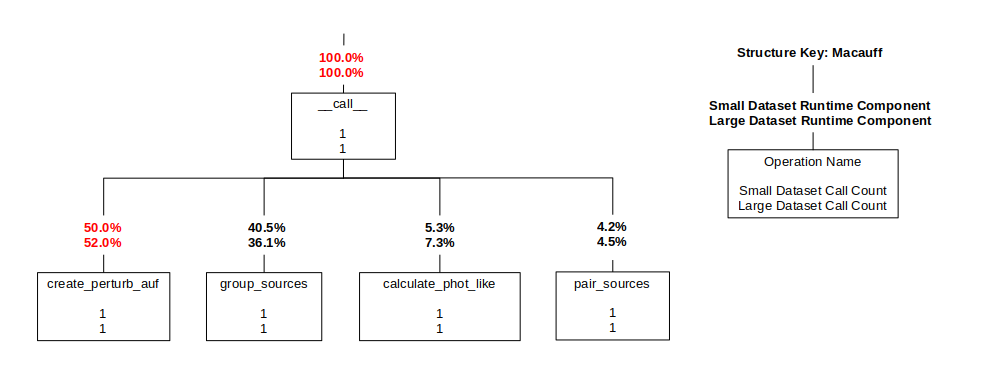
Above: Macauff structure diagram.
Results showed the Macauff application consisted of four stages (create_perturb_auf, group_sources, calculate_phot_like, and pair_sources) in a pipeline configuration where each subsequent stage required the full outputs of the previous stages.
Runtime proportions for both the small and large datasets were roughly similar, with no stage coming to dominate the runtime. This created a challenge for the parallelisation effort as, rather than a typical "main loop", each stage contained its own sub-loops over various data structures with differing iteration counts and interdependencies. Focus therefore shifted from the application itself to the input Gaia and WISE datasets, and to whether they could be decomposed across independently parallel processes.
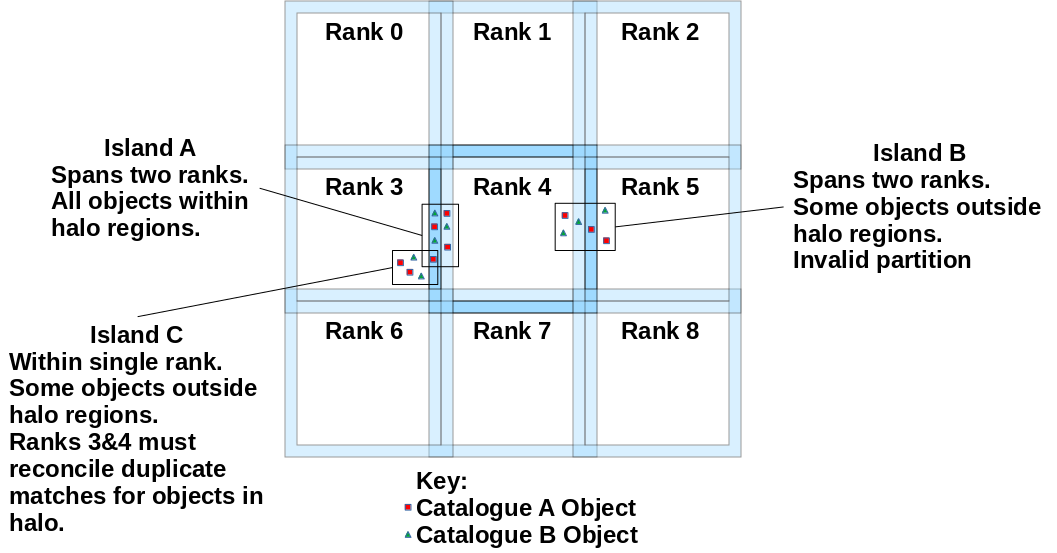
To split the dataset effectively, a solution was needed for any catalogue objects along decomposition boundaries which depended on information from a piece of the dataset located on a neighbouring process. The choice was made to divide the input catalogues into “chunks” with overlaps (aka halo regions) containing duplicates of objects from those of a neighbouring rank. Chunks would be shared across instances of the Macauff application. Essentially, rather than a single instance of Macauff cross-matching the entire sky, multiple Macauffs would be given small regions of the sky to cross-match separately.
Macauff matches are performed within "islands", collections of potentially matching catalogue objects. For an input decomposition to be valid, halo sizes must be decided such that no island spans processes without all its objects being contained within the halo region.
The halos introduced a further challenge: with duplicate objects came the potential for duplicate cross-matches, ie separate processes could produce their own conflicting identifications for a single object. This would affect only a fraction of matches but require reconciliation between ranks before final output.
The chosen approach was to output only the cross-match of the process which "owned" the object, ie the process with the object in its core rather than its overlap/halo, as this eliminated any need for cross-process communication.
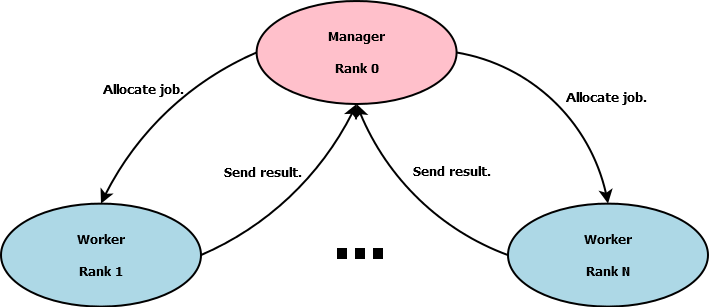
Of further consideration was application load balancing. Chunks would not be of uniform size, each would have differing object counts, therefore taking more or less computation time to cross-match. A task farm approach using MPI, the Message Passing Interface standard for parallel computing, was implemented where one process is designated the "manager" and allocates "jobs" (chunks) to the remaining "worker" processes. In MPI, all processes are given unique numerical IDs or "ranks" with rank 0 being set as the manager. This solution allowed the application to naturally load balance through the manager serving new chunk requests to workers as completion notifications were received.
This provided an effective approach for speeding up computation but there was another bottleneck to consider: I/O.
Observed during test runs of Macauff were a number of temporary files produced and deleted throughout the matching process. The application had employed memory-mapped files to back most major data arrays and reduce memory pressure, resulting in tens of files produced per pipeline stage. Running the pipeline stages in parallel would therefore produce these files in parallel, with more files produced per additional worker process added to the job. At scale, this would stress the file system with excessive metadata and other I/O
operations, potentially bottlenecking the scalability of Macauff.
As input catalogues had been reduced to small chunks to implement the task farm, memory pressure was less of a concern, a process's memory high water mark could be lowered by providing smaller input chunks. Each memory-mapped array was thereby replaced with a typical Numpy array to eliminate the need for temporary files. This endeavour required close collaboration with the University of Exeter developers who examined Macauff outputs regularly between code updates to ensure functionality did not change.
Finally, new features were added to Macauff to improve the resilience of large scale jobs. Checkpointing, allowing cross-matches to be resumed if interrupted, was implemented through a tracking file maintained by the manager process . The manager records chunk IDs as workers report successful completion and, on resumption, allocates only those chunks not already recorded as complete. Recovery of failed workers was made possible through catching any exceptions generated during chunk processing and reporting the error to the manager process. The manager logs the error for future investigation and allocates a fresh chunk to the now idle worker.
Test runs of the final code achieved efficient scaling to over 7000 cores on CSD3, with the potential for further efficiency gains with tuning of job parameters. Expected runtime for an LSST-scale cross-match is now days to a week, rather than months to a year, enabling astronomers to more effectively pursue scientific discovery.
Links
You can read about another EPCC collaboration with LSST:UK in this article on our website: Accelerating the simulation of galactic images with OpenMP Target Offload.